Why Reverse ETL Is Quietly Replacing Traditional Marketing Data Pipelines
What Is Reverse ETL?
Reverse ETL is the practice of moving data out of your central data warehouse (or lake) and into the tools that activate on it—email platforms, ad networks, CRMs, lifecycle tools, and so on. Traditional ETL (and ELT) brings data into the warehouse; reverse ETL pushes curated tables, attributes, and segments from the warehouse to downstream systems on a schedule or in near real time. The warehouse stays the single source of truth; activation tools receive only what they need to run campaigns, personalize experiences, and measure performance.
The Traditional Pipeline Model—and Its Cost
Traditional marketing data pipelines are sophisticated and they work: DAGs, tools like Airflow, Python scripts, and custom jobs that extract, transform, and load data into marketing databases or directly into activation systems. Once designed and built, the main job is maintenance—fixing breaks, updating outdated code, and responding to new data or schema changes. That maintenance falls to data engineers, who are expensive and in high demand. They're worth too much to spend their time keeping pipelines running. Their highest leverage is elsewhere: core data systems, internal data flow, data availability, governance, security, and speed of access.
The other problem is ownership. Marketing and lifecycle teams can't own or meaningfully contribute to these pipelines. When something goes down or a new attribute is needed, a specialist has to step in. That creates bottlenecks, slows campaign velocity, and keeps activation dependent on engineering capacity. The philosophy we want is the same one we apply to lifecycle managers: simplify the operational work so people can spend more time on what actually matters—for data engineers, that's complex data systems and governance; for ops and lifecycle, that's design, testing, inference, experimentation, and optimization.
Reverse ETL doesn't replace the need for a strong data foundation (tools like dbt remain central to modeling and transformation in the warehouse and can be a core part of a composable MarTech stack). What it does is democratize the last mile: the flow of data from the warehouse to activation. Putting definitions, schedules, event enrichment, and user-profile trait creation in the hands of ops and lifecycle managers increases campaign velocity and gives everyone more time for higher-thought work.
Why Teams Move to Reverse ETL
The main reason teams move is simple: they want to access more data, and demand has outstripped what data engineers can keep up with. The default response—hire more engineers—runs against a better philosophy: don't add headcount to systems that don't need it until you've automated the work you can. Reverse ETL is one of those automations. It lets ops and lifecycle define syncs, attributes, and audiences from the warehouse without writing DAGs or waiting on engineering tickets.
This also fits how we think about people. As a leader, it matters what direct reports want to do, what they don't want to do, and where they want to grow. Simplifying the mechanics of data flow gives marketing teams the ability to operate without constant engineering dependency, and it gives data engineers room to specialize in higher-impact work. The result is faster iteration, more self-service, and a clearer path for everyone to focus on design, testing, and optimization instead of pipeline maintenance. For more on structuring the team that runs this kind of stack, see "The Perfect MarTech Team".
Why This Shift Is Happening "Quietly"
The move to reverse ETL is real but not loud. It's quiet because it's moving relatively slowly: it requires a high-functioning, high-thought-power MarTech team to understand the benefits and implement it well. It requires a significant budget to initiate—warehouse, modeling, and reverse ETL tooling. It requires convincing traditional marketing managers who aren't necessarily trained in logic or complex systems that this will benefit them. And it requires thoughtful leadership to support the vision and contribute to the roadmap. Compared to the noise around AI and other tech breakthroughs, reverse ETL isn't being talked about in the same circles—but progress is happening. Teams that make the shift gain a durable advantage in data access and campaign velocity.
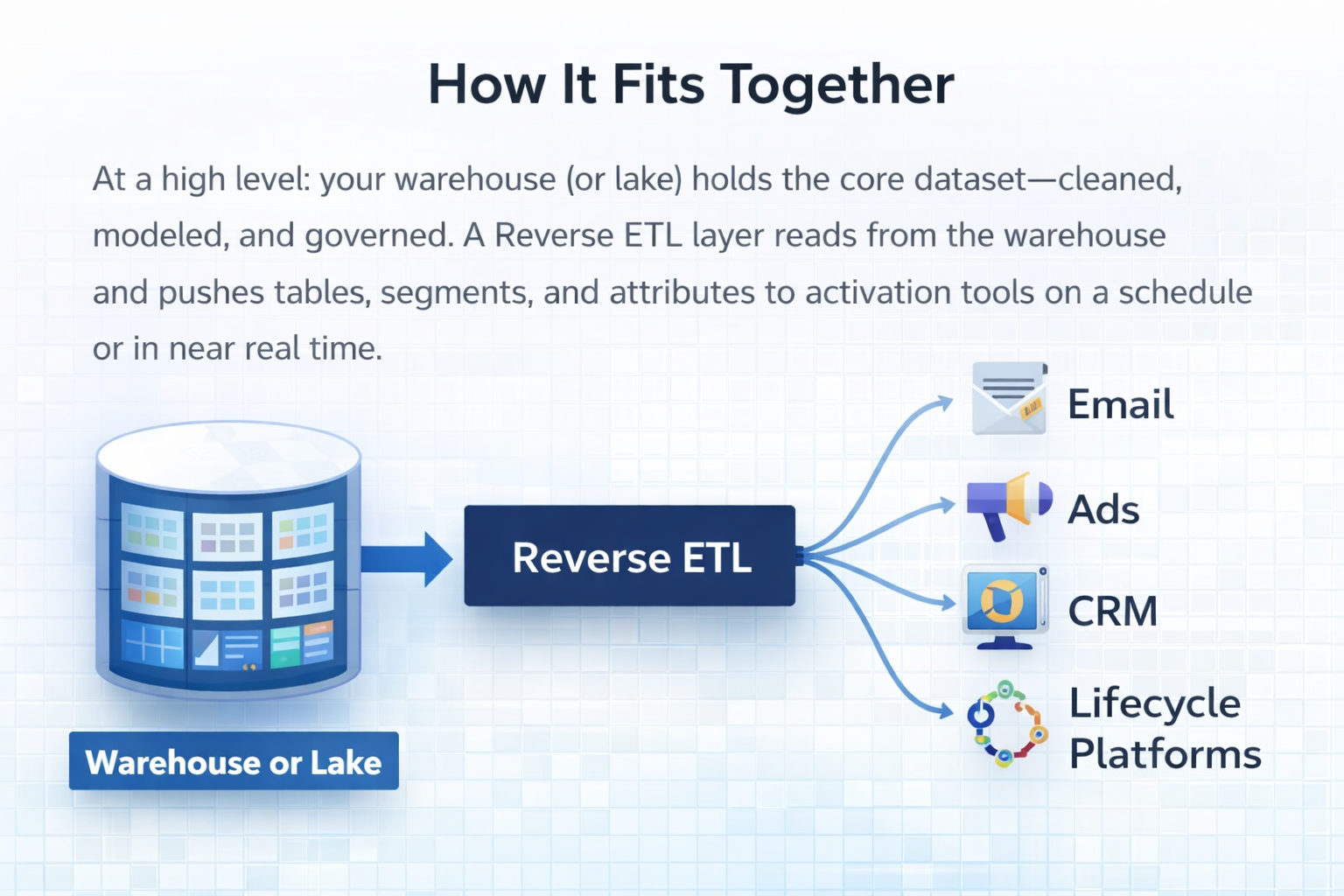
How It Fits Together
At a high level: your warehouse (or lake) holds the core dataset—cleaned, modeled, and governed. A reverse ETL layer reads from that warehouse and pushes tables, segments, and attributes to activation tools (email, ads, CRM, lifecycle platforms) on a schedule or in near real time. You own the definitions and the schedule; the reverse ETL tool handles the sync, mapping, and API calls. This fits the same hub-and-spoke mental model described in "Migrating From a Marketing Suite to a Composable Stack": one core dataset, one place to refine it, and controlled push to many destinations.
Caveats and Prerequisites
In a well-designed composable stack, reverse ETL should work with any destination you need. If a tool or use case "doesn't fit" reverse ETL, that's often a sign the tool isn't built for warehouse-native activation—or that your reverse ETL layer isn't the right fit. The principle holds: you're pushing from a single source of truth to many systems; that pattern should be universal.
Starting with messy or incomplete data isn't ideal, but it can be done—and a benefit of the composable stack and reverse ETL model is that you're not stuck if you do. You can spend time refining your data and then switch out the data sources: point the same sync layer at improved tables without rebuilding the whole pipeline. That pointer system is what lets you assume a little tech debt up front and pay it down later by swapping the core dataset, instead of having to perfect the data before you can activate on it.
One Team's Outcome
A practical example: a team replaced an Airflow-based pipeline with a warehouse-centric setup using Hightouch, Google Big Query, and Databricks. The ROI of the new platform paid off within a month of launch. It also became the basis for expansion into areas they hadn't been able to access before: self-service building of attributes and events, and the use of more raw data to define audiences more accurately. The same pattern—warehouse as source of truth, reverse ETL for activation—applies regardless of which tools you choose; the important part is shifting control of data flow to the people who need it.
Conclusion
Reverse ETL is quietly replacing traditional marketing data pipelines because it puts the power of data flow management—definitions, schedules, event enrichment, and user profile traits—in the hands of ops and lifecycle managers. That increases campaign velocity and gives employees more time for design, testing, inference, experimentation, and optimization. Data engineers can focus on core data systems, governance, and access; marketing can own activation without waiting on pipeline tickets. The shift requires a strong team, budget, and leadership support, but for organizations that make it, the payoff is real. For the broader architecture this fits into, see "The Perfect MarTech Stack" and "Migrating From a Marketing Suite to a Composable Stack".